How the IDMP Ontology and a simple 6-step approach support more effective and strategic implementation of the ISO IDMP standards in large pharmaceutical companies.
The goal of the ISO IDMP standards is to improve patient safety, and increase operational efficiency in cross-organizational collaborations e.g., in regulatory processes.
While originally published several years ago, from 2023, the IDMP standards get iteratively enforced by regulatory authorities such as the Europeans Medicines Agency (EMA) for drug submissions. Because of this pressure, most pharma implementations of IDMP are focused entirely on the regulatory submission process. While this may seem like a valid strategy at first glance, for many companies, this strong process orientation has turned into a focus on a vendor- or system-specific implementation - often far away from IDMP data standardization. We observe that this has led to substantial implementation costs, significant implementation delays, a complete failure in some cases, and the need to restart after several years of investment. This shows that it is a huge evolutionary step from a process-centric and purely document-oriented way of working toward data-centric management of structured information.
In this article, we outline how a data-centric IDMP implementation is complementary to the process orientation and allows utilizing the regulatory pressure to mitigate current issues and to significantly advance data management practices across various departments along the entire pharma value chain towards more structured information - incrementally and without the risk of big-bang solutions.
It Starts with Good Definitions
The IDMP standards cover key data objects, such as substances, products, manufactured items, and clinical trials that impact the entire pharma value chain connecting many different departments.
IDMP standardized data objects provide a massive opportunity for effective cross-organizational collaboration if deployed on an enterprise level.
E.g., linking substance information with clinical trials, products, manufactured items, suppliers, and safety signals. However, realizing these use cases in concrete IDMP implementations requires deep semantic interoperability in data definitions. This cannot be achieved by a document standard alone, as people interpret the published PDFs differently when it comes to implementation. That is why a group of pharma companies, including Bayer, Novartis, Roche, Merck KGaA, GSK, Boehringer Ingelheim, and Johnson & Johnson, have initiated the collaborative creation of an open source IDMP Ontology that augments the ISO standards with a digital semantic standard (more info at the Pistoia Alliance project website).
An ontology is nice, but we need more to solve actual problems with it. In the following subsections, we describe the 6 steps for a strategic and value-driven implementation of IDMP that aligns with established FAIR data management principles and that serves as a complementary workstream to the current process-oriented IDMP implementation.
The 6 Steps to Scalable Value Creation
While many IDMP implementations are mega-projects, the following 6 steps provide an agile methodology to incrementally realize value with a low risk of failure.
Step 1: Selection of Use Cases and Competency Questions
Due to the enormous scope of IDMP, we need to prioritize use cases to avoid getting lost. In practical terms, high-value use cases are broken down into a set of concrete Competency Questions (CQ) that must be answered with data. For instance, “Which investigational or authorized medicinal products contain substance S?” These CQs are later formalized into queries that can be executed and tested on data.
A good starting point for the identification of high value CQs is to examine issues or bottlenecks in the current business processes.
Let’s review the steps toward answering a CQ in detail to understand which level of integration and governance is required to answer a multitude of questions at an enterprise scale.
Step 2: Definition of Data Object Types and Relationships in the IDMP Ontology
After identification of a business-relevant data scope with Competency Questions, the next step toward data interoperability is to agree on good definitions for data object types such as substance, medicinal product, ingredient roles, etc. Of course, IDMP Ontology reuses the ISO definitions as far as possible, but it also refines and augments them as needed to meet formal semantic interoperability criteria. In simple terms, this means that in addition to textual definitions, object relationships are used to describe the objects semantically. For example, all ISO IDMP object types are structured in a formal is-a/sub-class hierarchy. You can browse the IDMP Ontology here after free sign-up.
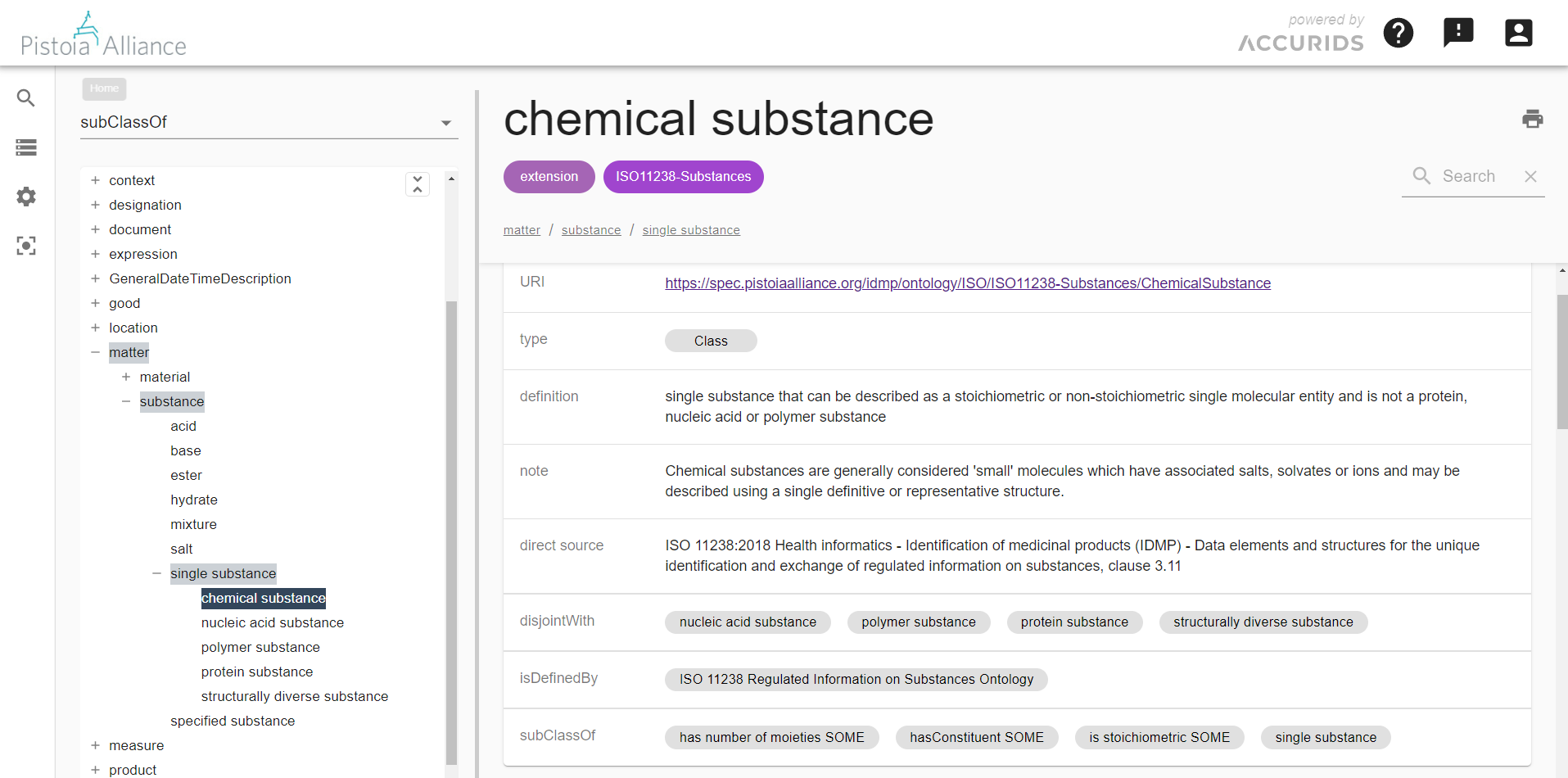
The open-source IDMP Ontology provides IDMP concepts with definitions and relationships based on formal semantics.
Note that the ontology allows the attachment of lexical synonyms to object types to address local naming preferences or conventions. E.g., “administered product” may be added as a synonym for the ISO standard object type “pharmaceutical product.” This allows for avoiding endless discussions about how to best name.
Step 3: Identification of Data Sources in the Data Catalog
With good definitions for data object types and relationships in place, the next step is to locate the data sources required for answering the CQs. Here, Data Catalogs are helpful because they not only list data assets but also have the documentation of the data structures needed to understand the data correctly. Thus, we can quickly get the data sources with substance information.

While a Data Catalog provides an overview of data assets, a catalog alone is not sufficient to answer CQs as it doesn’t have the actual data, i.e., data about substances or products. As illustrated above, a typical CQ asks about the relationship of different things, e.g., “What products contain substance <S>?” Of course, this can be much more complicated, but before we get there, we must reliably answer even simpler CQs: “What substance do we have?” and “What products do we have?” This requires globally unique identification, as described in the next step.
Step 4: Identification of Data Objects in the Data Registry
Answering even the most straightforward questions requires globally unique identification not only of medicinal products but of all data objects of all critical object types across all relevant data sources.
While the data sources can be found with a Data Catalog, obtaining a complete and consistent list of objects (e.g., list of substances, list of products, list of clinical trials) requires an Enterprise Data Registry. Through the registry, all data managing applications make transparent the type of data they manage (see Catalog) and the identifiers, names, etc. of the critical data objects they are responsible for.
The step from Data Catalog to Data Registry is crucial as we move from schema information to actual data.
From a governance and integration perspective, a Data Registry is a minimal augmentation of the Data Catalog that enables data collaboration across organizational or system boundaries without requiring complicated integration pipelines. With an Enterprise Data Registry, we establish central governance while allowing data management to remain distributed and performed by domain experts in their systems. The key functionalities of a data registry are persistent identifiers, search and object deduplication. Learn more about the Accurids Data Registry product.
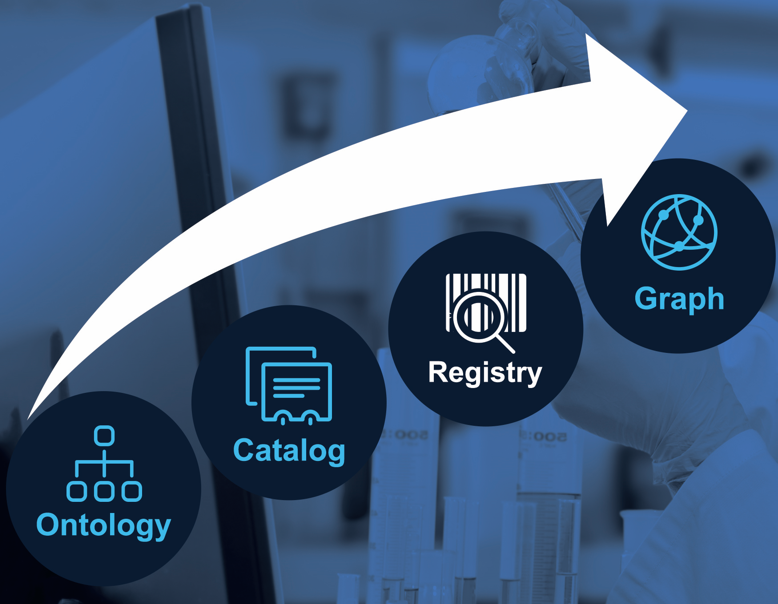
The Data Registry is the foundation for Enterprise Knowledge Graphs (EKG) described in the next step as it provides globally unique and persistent identifiers for the graph nodes - meeting FAIR principles.
Step 5: Integration of Data in an Enterprise IDMP Knowledge Graph
With all data object types semantically defined in the IDMP Ontology and all IDMP data objects in the scope of selected CQs registered, we have a stable foundation for building an Enterprise Knowledge Graph that allows us to realize a multitude of IDMP use cases. With regular anchor points, different data sources can now publish their information about substances, products, clinical trials, etc. For instance, a Product Life-Cycle Management system has information about products, their status, and product-substance relationships, while the GSRS system from FDA contains many different substance-substance relationships. Brought together in a knowledge graph, this can answer more complex questions such as “Which authorized products to contain substance S or other substances with the same active moiety as substance S?”. Instead of point-to-point integrations, we only require sources to publish data in standardized terms and data structures of the IDMP Ontology.

IDMP Ontology-aligned data is integrated by design and allows to provide a 360° data view combining data from different internal and public sources (here public data from the FDA's Global Substance Registration Service). Source: Screenshot from Pistoia Alliance Community of Interest Call from September 2022. To learn more about the IDMP Ontology project, visit the Pistoia Alliance Project Page.
Step 6: Utilizing the Knowledge Graph in Business Applications
Answering Competency Questions with queries is required in specific scenarios, but it is more of a methodology than a typical business user task. Thus, the last step of a successful IDMP implementation is to utilize data from the knowledge graph in business applications such as regulatory submission processes, ERP, or analytics dashboards. With a sustainable, IDMP-compliant data foundation in place, we can now incrementally expand the scope of the graph with more CQs (following steps 1-5) and ultimately realize many different application scenarios in a much faster time. The key here is understanding that applications and processes don’t own the data. Instead, data is a corporate asset that is collaboratively built and governed based on standards.
Summary
To become IDMP compliant, we need to have a shared IDMP Ontology and build a Knowledge Graph that allows answering questions about IDMP data objects to speed -up regulatory-related business processes and to fulfill regulatory requirements effectively. However, building KGs at scale has two prerequisites:
- A Data Catalog that documents relevant data sources
- A Data Registry based on FAIR principles that provide unique and persistent identifiers for IDMP-related data objects.
With both in place, we can build sustainable Enterprise Knowledge Graphs that scale regarding use cases and business value creation without the need for mega solutions with a high risk of failure.
You can schedule a demo to learn more about your individual use cases and the benefits your corporation can realise through the simple implementation of Accurids:
