Contrary to the common perception, reference and master data (RMD) is mainly managed in many different systems, not a central master system. Instead of fighting this reality with another centralization attempt, it is more effective to embrace the reality of distributed reference and master data management by providing simple mechanisms to publish, discover and exchange existing RMD across organizational and system boundaries. In this article, we outline critical functional capabilities for realizing a distributed approach in large organizations with multiple governance bodies and explain how the product Accurids helps to make the significant steps within a few months.
This article is based on a white paper from Heiner Oberkampf, Malcolm Chisholm, and Christian Senger.
What would a distributed reference and master data management environment look like?
To answer that question, we must consider what elements are necessary for distributed Reference Data Management to work. The following figure illustrates that some degree of centralization, or federation, is needed – not for management but to facilitate governance and accessibility. Any business unit that wishes to become an authorized source for some Reference or Master Data concept can do so by approval of the governance body. Any business user can discover official sources for a given RMD concept by looking it up in the Registry.
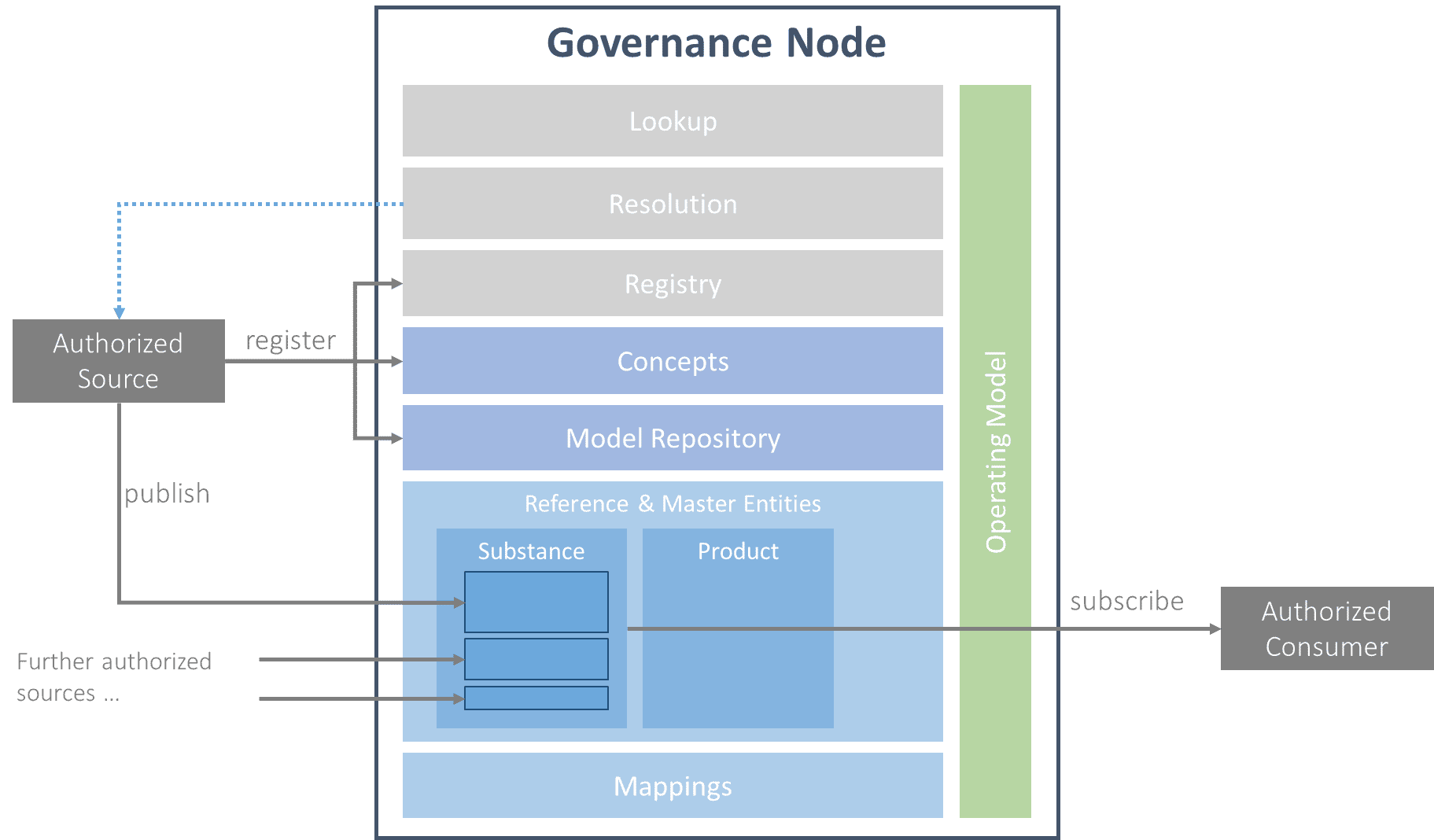
From this, we can see how distributed management and governance could work. It will foster standardization and a harmonized governance structure. Some degree of central governance is therefore required to ensure the standards and Registry exist and are well functioning. The eight critical components for this are described next.
Lookup: An enterprise-wide solution that permits anyone in every business unit to discover all registered concepts and then be able to obtain the relevant information. This means we need a central LOOKUP service for users to search and find any used term or identifier. The lookup service needs to support state-of-the-art search and filter capabilities and contextualized ranking to enable users to see entities or detect gaps.
Registry: From a technical side, having a REGISTRY for any reference and master data entity can be considered as a technical pre-condition for distributed RMDM. Registrations happen on the source, concept, model, and entity levels. An AUTHORIZED SOURCE is a system or organization registered on the governance level for one or more data domains and corresponding specific concepts. After registration, the source can register and publish corresponding RMD entities.
In alignment with the FAIR guiding principles, the Registry assigns all data and metadata a globally unique and persistent identifier.
- Resolution: In a distributed environment, it may be the case that not all information is loaded to the Governance Node from an authorized source. The RESOLUTION serves as an API for all information loaded into the Governance node and allows to redirect or assemble information in an ad-hoc manner from trusted sources. Again, companies will need a standard to access RMD from the points at which it is being maintained.
- Concepts: To quickly find and facilitate integration, we must carefully define the types or CONCEPTS under which authorized sources will publish RMD entities. Examples are substance, equipment, indication, or disease. Since the agreement, even on the concept level, may be difficult, we only require that concepts are well defined and linked to each other, at least partially as a well-formed taxonomy with strong subclass relationships. For more substantial alignment, companies may capture concepts in an ontology.
- Model Repository: Data models are at the heart of data integration. Getting the approach to data modeling right has massive potential for the digital enterprise and the ability to create data products. An enterprise-wide solution will be difficult to use if every Reference Data concept is implemented with a completely different structure to every reference or Master Data concept. It will be even more challenging to use if every concept has to undergo source data analysis by any team that needs it. This implies there must be a mechanism for standardization of RMD implementation in terms of structure.
- Reference and Master Data Entities: RMD Entities are identified with a globally unique persistent identifier from the Registry, which the resolution component can resolve. According to the model stack, for every entity, governance information is available, and a reference to a common semantic concept should be given to increase discoverability. Entities of the concept should be harmonized regarding content as far as possible, e.g., the required attributes, filled values used in reference lists, units, and label style. The core entities of the enterprise needed for data products should be identified, and blueprints should be created to assist with integrating any non-standard entity.
- Mappings: Mappings are used to align RMD from different sources where companies cannot avoid the overlap due to historical or business process reasons. It is not always possible to define all-agreed data mappings. What is regarded as the same and what is different can be a question of perspective? Thus, data mappings must be contextualized so that different perspectives can be captured. Additionally, users can express similarity with SKOS or similarity scores.
- Operating Model: Distributed management of RMD does not mean anarchy. Yet, this is likely to happen if we say that anyone in the organization is free to manage any Master Data or Reference Data without providing governance guidelines. The main reason that anarchy is a likely outcome is that it is not clear what has to be done to manage RMD in general, let alone in a distributed environment. So we can easily imagine that for, say, a particular Reference Data concept, the owner does not know what tasks have to be done to manage the implementation, realize that some functions have dependencies, or understand who will be the best person to carry out a particular task. Therefore, the possibility of different people clashing because of a lack of clarity about accountabilities is a risk.
The best response to meet these core governance needs is to develop an operating model covering roles, responsibilities, policies, and standards. An operating model identifies the functions that are needed in a particular context and what is expected in general from these roles.
How does Accurids support distributed reference data management?
Today, many enterprise data strategies aim to centralize reference and master data management to regain control. Though there are legitimate reasons and interests to consolidate, Accurids is built on the observation that centralized management alone is too slow to accommodate the fast-changing IT and data landscape. Pure centralized approaches fail to support different business units' diverse perspectives and incompatibilities in large organizations. Both aspects are increasingly important in the era of digitalization and the increased need for collaboration across enterprise boundaries.
Accurids is a registry for distributed reference and master data. It serves as a discovery solution and provides reliable access for anyone in your organization to reference data managed in different applications. It can be used as the foundation of a reference and master data strategy.
The key functions of Accurids are
- Global Lookup service allows searching for any term or code used within the enterprise. Global Lookup enables data stewards to find the preferred terminologies for a given domain and encourages re-use instead of re-creation.
- Persistent Identifiers can be generated to provide long-term stable and resolvable IDs that provide data references that users and applications can rely on – even when the place where the reference data is managed changes. Persistent IDs are required for FAIR data.
- Matching reference data is essential to aligning existing terminologies that are already used. Accurids automatically generate matching proposals, and data stewards need to review and approve suggestions before mappings become available.
- Public standard terminologies such as the Gene Ontology, the NCBI taxonomy or an IDMP-Ontology can be imported into Accurids with 1-click so that all internal consumers use the same, latest, and validated version.
Leading global pharmaceutical companies are already utilizing Accurids and see the ROI. With this white paper on the ROI of reference and master data management, You can calculate your data strategy's money and efficiency gains.
You can schedule a demo to learn more about your individual use cases and the benefits your corporation can realise through the simple implementation of Accurids:
